
Introduction
- XPath in Selenium : X-path refers to the XML path. XML path provides the precise location of the Web Element. It helps to traverse the HTML structure from the origin to the destination of the webpage to find the exact position of the Web Element.
- The XML (eXtensible Markup Language) Path Language (XPath) is used to identify or address parts of an XML document uniquely.
- An XPath expression can be used to search through an XML document and extract information from any part of the document, such as an element or attribute in it.
- In this guide we will walk you through to learn how to use XPath in selenium
What is XPath in Selenium?
- XPath in selenium is an XML path used for navigation through the HTML structure of the page.
- Selenium uses different ways to locate the web elements. The primary way to locate the element is by using the basic locator’s id, name, class name, link text, and tag name.
- Sometimes the web elements in the Dom will not have proper attribute values. For example, the attribute id will have auto-generated numbers; likewise, names, tag names, and class names will sometimes be duplicated, and the values will have special characters and white space. At that time, I will go with XPath.
Why do we go for XPath?
Selenium automation has primary locators like ID, name, class, link text, and partial link text. When the elements cannot be located, XPath is used to locate those elements on the webpage.
Xpath is preferably considered when,
- There are no other standard locators available like id, name, etc.
- The locators are not stable.
- Having multiple values (duplicated).
- Id= “ext-gen869”-even though the id is considered a reliable locator, we cannot use it as it contains a number and is dynamic (subject to change).
- Class=”x-grid3-col x-grid3-cell x-grid3-to-friendlyPartyName”-> the class name has special character it also cannot be used as basic locator to identify this particular element. In these cases, XPath methods accurately locate the web elements.
How do we write XPath?
| Expression | Description |
| node name | Selects all nodes with the name “node name“ |
| / | Selects from the root node |
| // | Selects nodes in the document from the current node. |
| @ | Selects attributes |
Types of XPATH
Based on the logic, XPath is broadly classified into two categories
- Absolute XPath
- Relative XPath
1.Absolute XPath
Absolute XPath ->locates the element starting from the root element (HTML) to the destined web Element.
- Absolute XPath-> refers to the direct way of finding an element. The major drawback of Absolute XPath is that the XPath will fail if there are any changes in the element’s path.
- The XPath begins with a single forward-slash (/), which states that the element can be selected from the root node. The root node is <html> following. We can write node by node to get the exact match
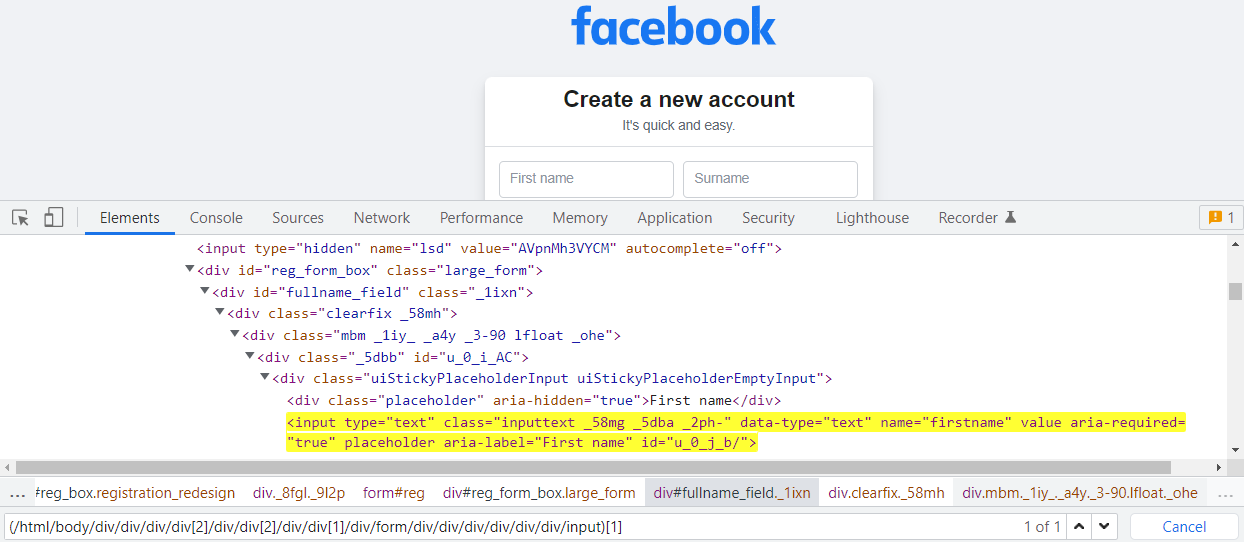
How to write Absolute XPath:
(/html/body/div/div/div/div[2]/div/div[2]/div/div[1]/div/form/div/div/div/div/div/div/input)[1]
2.Relative XPath
- Relative XPath – starts from the middle of the HTML DOM structure. It begins with a double forward-slash (//).
- It can search elements anywhere on the webpage, which means there is no need to write a long path, and you can start from the middle of the HTML DOM structure.
- Relative XPath is always preferred as it is not a complete path from the root element.
Relative XPath We can write by using the following ways,
- Attribute Based XPath
- Text() Based XPath
- Contains() Based XPath
- Collection Based XPath
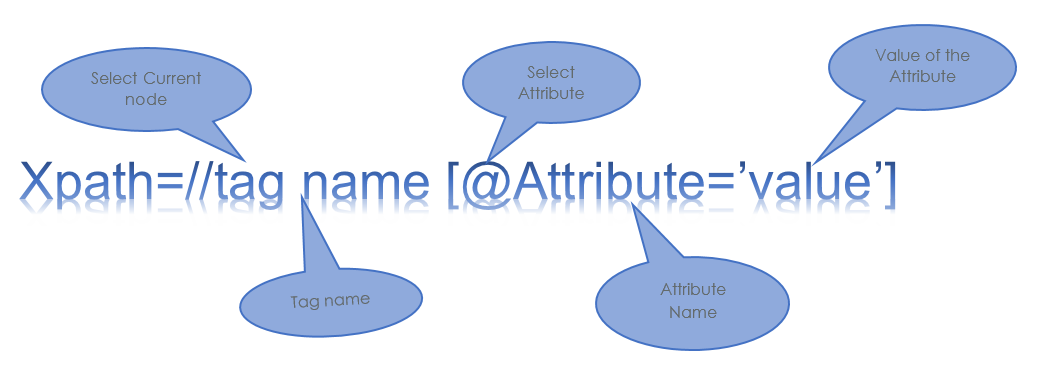
1. Attribute-Based XPath
We locate a particular node in the DOM page by using the attribute.
Syntax to write the Attribute Based XPath:
Example:
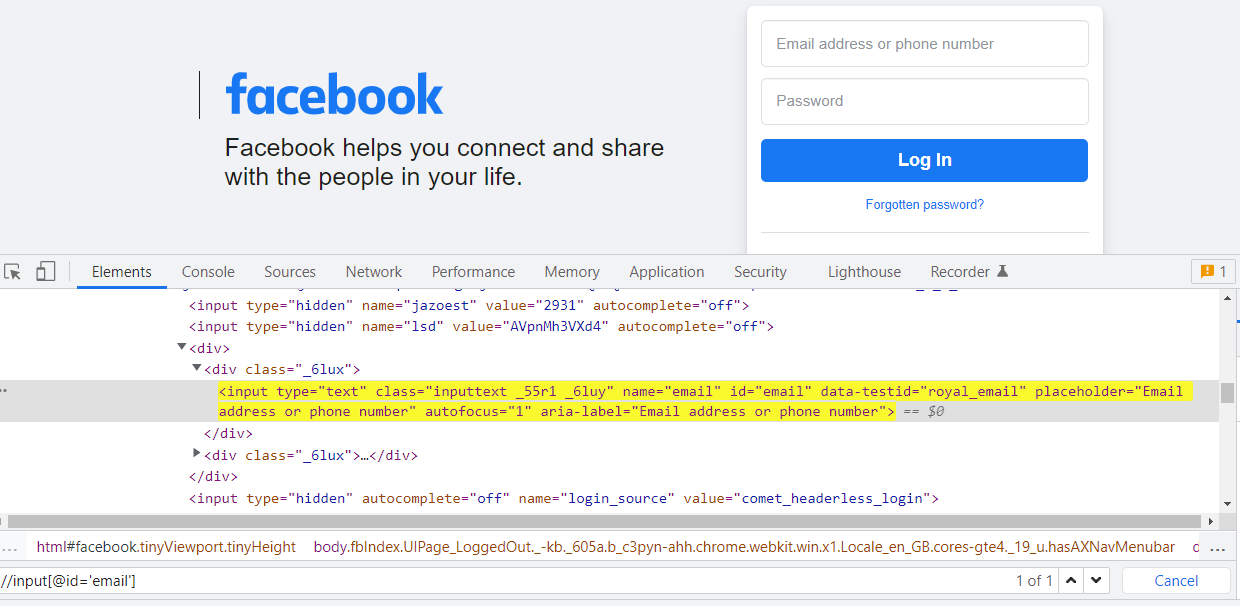
How to apply XPath as a Script
driver.findElement(By.xpath(“//input [@id=’email’]”));
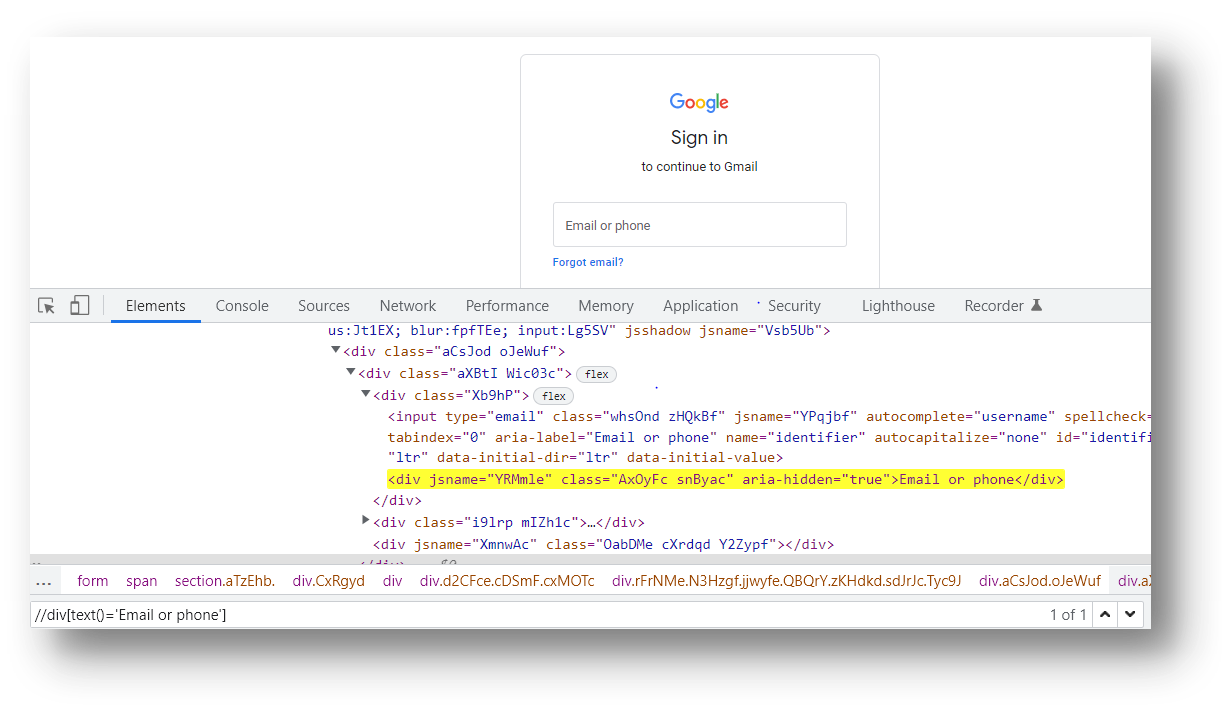
2. Text () Based XPath
The XPath Text () method is used to locate the element on a web page using the web element’s text. The function proves its worth if the element contains a text.
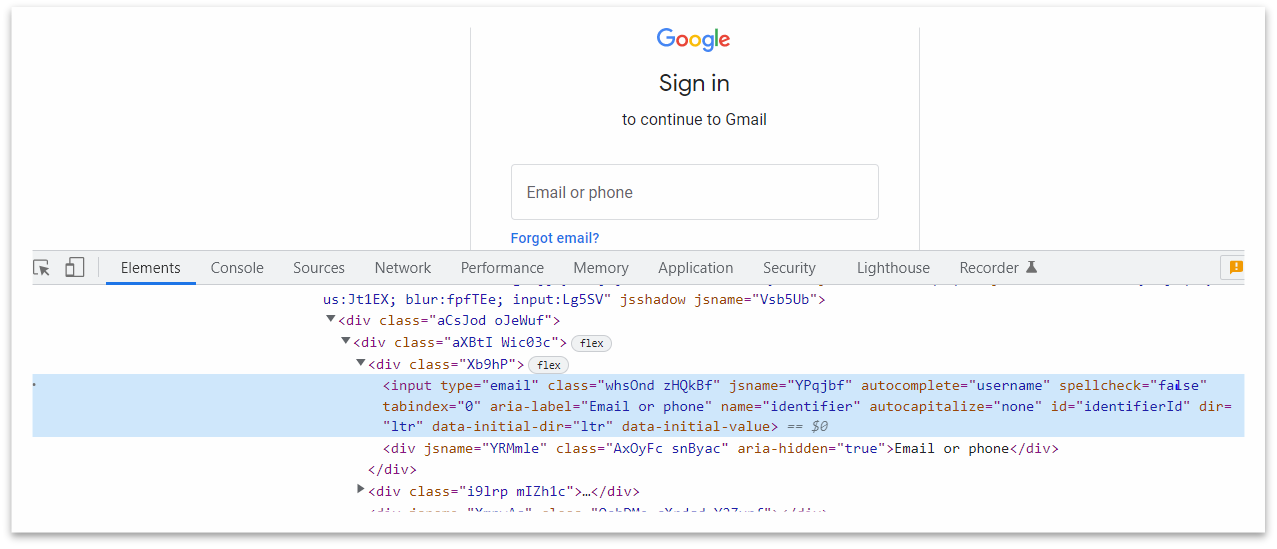
Syntax for text () method:
//tag name [text () =’black colour text’]
3. Contains () Based XPath
When the element attributes are changing dynamically. Using contains, we can select elements based on their partial texts. It uses Contains () method to match the partial value of the attribute. Partial match XPath is of two types
a) Partial Text Based XPath: =>uses the partial text value of the web Element
Syntax Partial Text Based XPath:
//tag name [contains (text (),’ Partial text in my DOM’ ‘)]
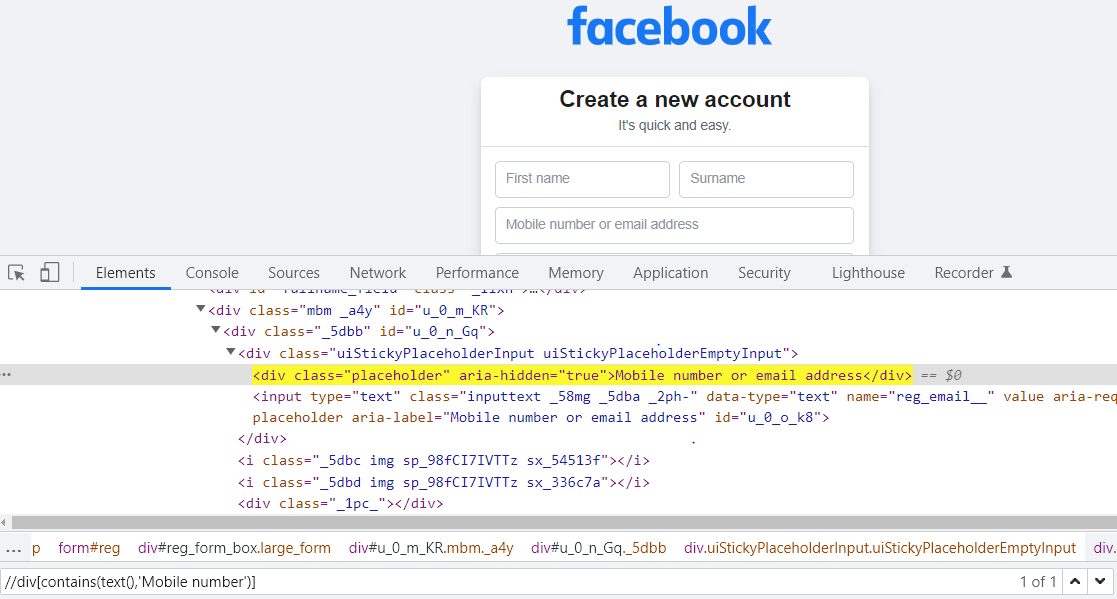
Example:
// label [contains (text (),’Create ‘)]
Partial attribute Based XPath: =>uses the partial attribute value of the Web Element
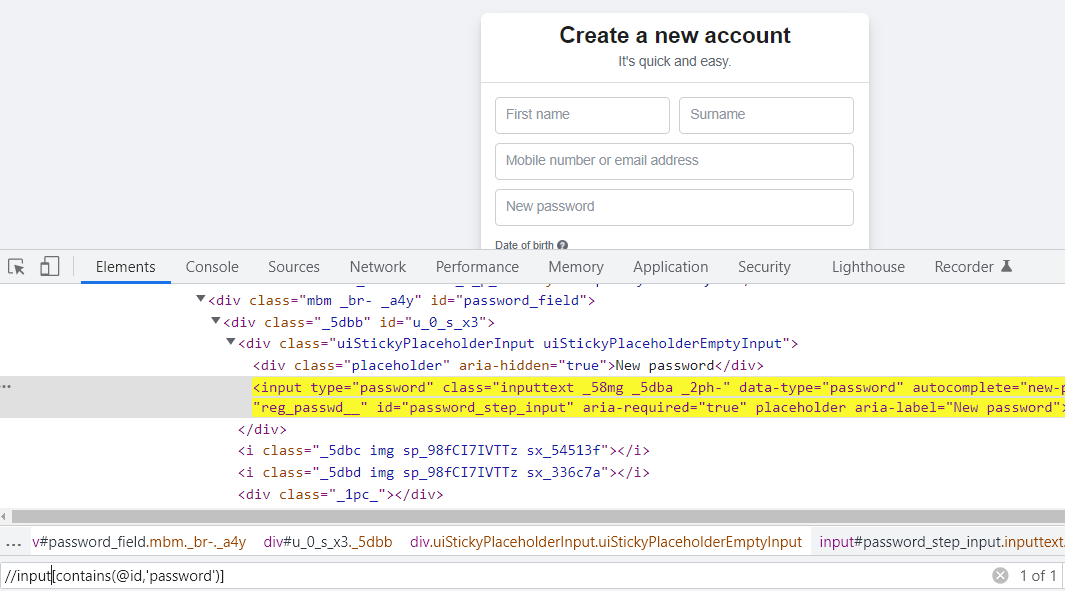
//tag name [contains (@attribute, ‘Partial value of the attribute’)]
Example
//input [contains (@id, ‘password’)]
4. Collection Based XPath
The collection-based path is usually used when there are multiple matches of a Web Element in the Dom. It uses index values to locate the particular match. Index of the XPath starts from 1.
Syntax Collection Based XPath
(Any Valid XPath)[Index]
Example:
(//tag name [@attribute=’value’])[1]
(Or)
(//tag name [text () =’text here’])[1]
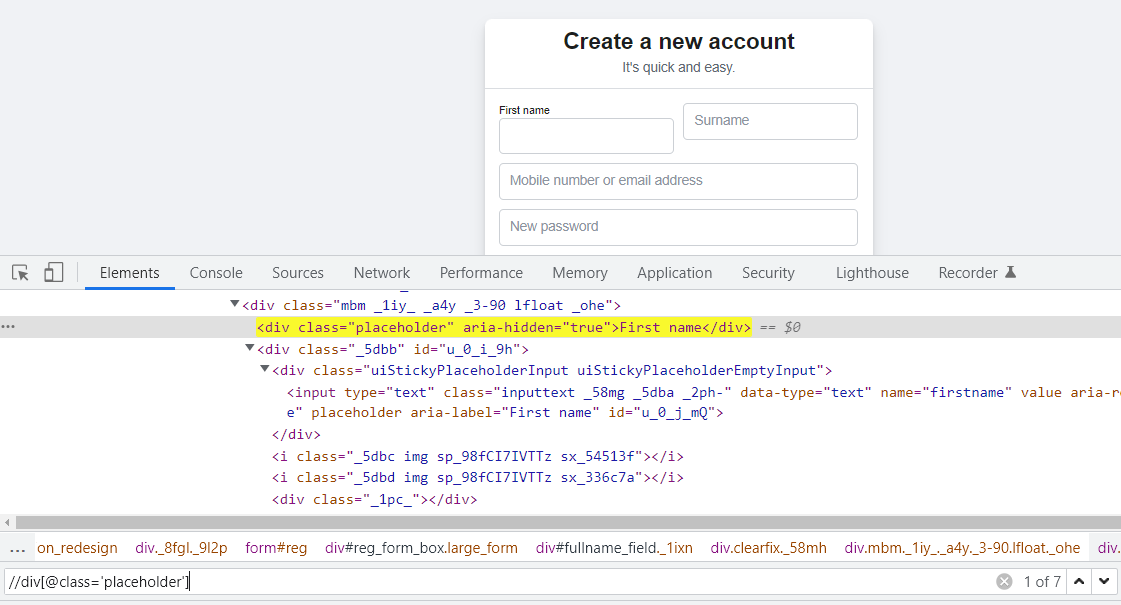
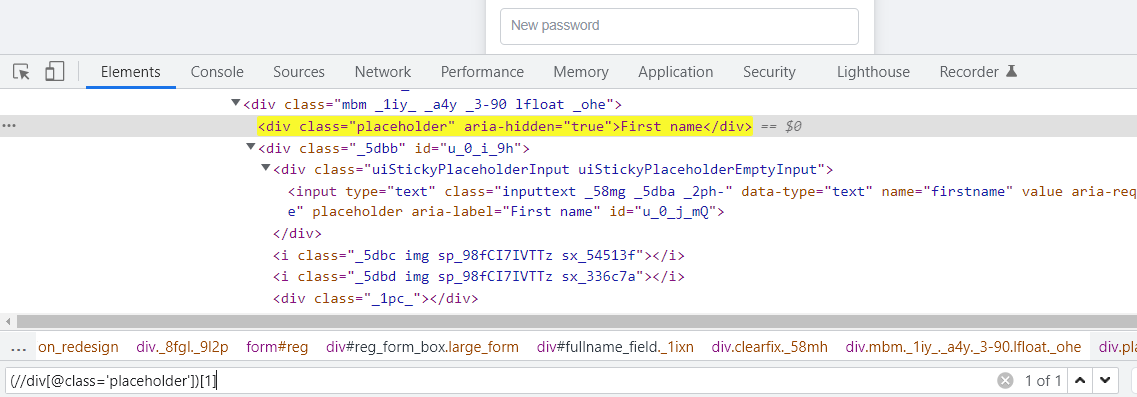
*Note: if the Index is not mentioned, then the driver matches the first resulting match of the Web Element.
Exceptions
The exception you will get when the driver could not locate the right Web Element
*No Such Exception->not a valid XPath
*Invalid Selector->refers to the syntax error in the XPath
Wrapping Up
If you are looking for a great way to learn how to use XPath and Selenium to automate your testing, check out our Selenium WebDriver training course. This training course will teach you everything you need to know to use XPath and Selenium effectively.
Author’s Bio:

As CEO of TestLeaf, I’m dedicated to transforming software testing by empowering individuals with real-world skills and advanced technology. With 24+ years in software engineering, I lead our mission to shape local talent into global software professionals. Join us in redefining the future of test engineering and making a lasting impact in the tech world.
Babu Manickam




