
Q.1. Can you elaborate on the distinctions between StringBuffer and StringBuilder?
Explanation:
StringBuffer: StringBuffer and StringBuilder classes are mutable.StringBuffer is synchronized i.e. thread safe. It means two threads can’t call the methods of StringBuffer simultaneously. StringBuffer is less efficient than StringBuilder.
StringBuilder: StringBuilder is non-synchronized i.e. not thread safe. It means two threads can call the methods of StringBuilder simultaneously.StringBuilder is more efficient than StringBuffer.
In Java, StringBuffer and StringBuilder are both classes that represent mutable sequences of characters. The key difference is that StringBuffer is thread-safe, meaning it is synchronized and can be safely used by multiple threads concurrently. On the other hand, StringBuilder is not thread-safe, making it more efficient for single-threaded operations.
Code Snippet:
// Example code using StringBuilder in a Selenium context
StringBuilder urlBuilder = new StringBuilder("https://example.com/search?");
urlBuilder.append("keyword=").append(userInputKeyword);
urlBuilder.append("&category=").append(userInputCategory);
String finalURL = urlBuilder.toString();
// Now 'finalURL' can be used in navigating to the dynamically generated URL in Selenium.
Exception:
NullPointerException might occur if the userInputKeyword or userInputCategory is null. To handle this, we check if the inputs are not null before appending them to the StringBuilder.
Challenges and Solutions:
-
Challenge 1: One challenge we face is managing concurrent access in a multi-threaded environment when using StringBuffer.
Solution: If thread safety is not a concern, we prefer using StringBuilder for better performance. -
Challenge 2: Handling dynamic changes in the input data and updating the StringBuilder accordingly.
Solution: We regularly update the StringBuilder based on changing user inputs or external factors to ensure the URL remains accurate.
Q.2. Can you elaborate on the concept of static methods?
Explanation: In Java, a static method belongs to the class rather than an instance of the class. It is associated with the class and not with objects of the class. Static methods are defined using the static keyword and can be called directly on the class without creating an instance of the class. They are commonly used for utility methods, where the behavior is not dependent on the state of any particular object.
Scenario: In my project, we have a convenient way of reading data from Excel files. We’ve created a static method, which is like a standalone function, specifically designed for reading data from Excel. This method does the job of extracting data from Excel sheets.Now, to make use of this method in different parts of my project, we’ve organized things into a base class. This base class has a method called dataProvider. Instead of duplicating the code to read Excel data in every class that needs it, you’ve centralized this functionality in the static method. Now, whenever any class needs data from Excel, it can simply call the dataProvider method in the base class, which in turn calls the static method responsible for reading Excel data. This way, we’ve created a clean and reusable approach for handling Excel data throughout your project. that are not tied to the state of a specific web page or element.
Code Snippet:
public class ReadExcel {
// Static method to generate a random email address
public static String[][] readExcelData() {
//code to read data from excel
}
}
// In another class or test script
public class BaseClass {
@DataProvider
public String[][] sendData() {
return ReadExcel.readExcelData();
}
}
- Challenge 1: Limited Access to Instance Variables
Solution: Static methods cannot directly access instance variables. If needed, pass them as parameters or make them static variables.
- Challenge 2: Inheritance and Overriding
Solution: Static methods cannot be overridden, and they are associated with the class at compile time. Be mindful of this when designing class hierarchies. Exception: No specific exceptions are associated with using static methods. However, improper handling of static methods, such as relying heavily on mutable static variables, might lead to issues like data inconsistency or unintended side effects.
Q.3. Can you elaborate on the practical aspects of abstraction in Java, especially concerning its application in real-world scenarios.
Explanation: Abstraction is hiding the implementation details and showing only the essential features of an object. It allows you to focus on what an object does rather than how it achieves its functionality. In Java, abstraction is achieved through abstract classes and interfaces. Abstract classes can have both abstract (unimplemented) and concrete (implemented) methods, while interfaces can only have abstract methods.
Scenario: In my project, abstraction is applied when creating a Page Object Model (POM). Abstract classes or interfaces are used to define a set of common methods or elements that are shared across multiple web pages. Each concrete page class then extends the abstract class or implements the interface, providing its own implementation for specific elements or actions.
Code Snippet:
// Abstract class defining common methods for web pages
public abstract class BasePage {
// Common method to click on a button
public abstract void clickButton(String buttonId);
// Common method to enter text in a text box
public abstract void enterText(String textBoxId, String text);
}
// Concrete class implementing the abstract class
public class LoginPage extends BasePage {
// Implementation of clickButton for the LoginPage
@Override
public void clickButton(String buttonId) {
// Perform specific actions for clicking a button on the login page
}
// Implementation of enterText for the LoginPage
@Override
public void enterText(String textBoxId, String text) {
// Perform specific actions for entering text in a text box on the login page
}
}
Exception: Exceptions associated with abstraction are usually related to the concrete implementations of the abstract methods. For instance, if an abstract method is not implemented in a concrete class, a compilation error will occur.
Challenges and Solutions:
- Challenge 1: Defining the Right Abstraction Level
Solution: Carefully analyze the commonalities among different classes to determine what should be abstracted. Refine and evolve the abstraction as the project progresses.
- Challenge 2: Keeping Abstraction Consistent
Solution: Regularly review and update the abstract class or interface to ensure it accommodates changes in requirements. Communicate any changes to the concrete classes to maintain consistency.
Q.4. Can you override static methods in Java?
Explanation: In Java, static methods belong to the class rather than instances of the class. Unlike instance methods, static methods are associated with the class and not with an object. Therefore, they cannot be overridden in the traditional sense because overriding is associated with dynamic dispatch based on the runtime type of an object.
Reference Links: https://docs.oracle.com/javase/tutorial/java/javaOO/classvars.html
Scenario: In my project, we faced a scenario where we had a base class with a static method for logging. We might have a requirement to customize the logging behavior in a subclass for a specific module or feature. However, since static methods cannot be overridden, we would need to use a different approach, such as creating an instance method and then using it through an instance of the subclass.
Code snippet:
// Base class with a static logging method
public class BaseClass {
public static void logMessage(String message) {
System.out.println("BaseClass: " + message);
}
}
// Subclass attempting to "override" the static method (not possible)
public class SubClass extends BaseClass {
// This method does not override the static method in the base class
public void logMessage(String message) {
System.out.println("SubClass: " + message);
}
}
- Challenge 1: Lack of Polymorphism
Solution: Instead of attempting to override static methods, leverage interfaces, and instance methods to achieve polymorphism and customization in subclasses.
- Challenge 2: Limited Flexibility
Solution: Use design patterns like the Strategy Pattern or Dependency Injection to allow flexible behavior modification without relying on static methods.
Q.5. What is a lambda expression in Java?
Explanation: In Java, a lambda expression is a concise way to express an anonymous function (a function without a name) that can be passed as an argument to methods or used as a part of a functional interface. It facilitates writing more readable and maintainable code by reducing boilerplate code associated with anonymous classes.
Reference Links: https://docs.oracle.com/javase/tutorial/java/javaOO/lambdaexpressions.html
Scenario: In the context of a Selenium project, you might use lambda expressions when dealing with functional interfaces, such as WebDriverWait. For example, you can use a lambda expression to express the condition for waiting until a certain element is clickable.
Code Snippet:
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(10));
// Using an anonymous class
WebElement element = wait.until(new ExpectedCondition<WebElement>() {
@Override
public WebElement apply(WebDriver driver) {
return driver.findElement(By.id("someElementId"));
}
});
// Using a lambda expression
WebElement element = wait.until((WebDriver d) -> d.findElement(By.id("someElementId")));
- Challenge 1: Understanding Functional Interfaces
Solution: Ensure a good understanding of functional interfaces and the method signature of the abstract method within the interface.
- Challenge 2: Handling Checked Exceptions
Solution: Use appropriate exception handling mechanisms (try-catch or propagate exceptions) when dealing with lambda expressions that involve methods throwing checked exceptions.
Explanation: In Java, the “this” keyword is a reference variable that refers to the current object. It is commonly used to eliminate ambiguity between instance variables and parameters with the same name, and to invoke current object’s methods. It’s especially useful in constructors and setter methods.
Scenario: In my project, we have employed “this” when working with Page Object Models (POM) for a scenario where a web page object has instance variables representing elements, and constructor parameters have the same names. Using “this” helps distinguish between instance variables and constructor parameters, improving code clarity.
Code Snippet:
public class LoginPage extends BaseClass{
public LoginPage(ChromeDriver driver) {
this.driver = driver;
}
//action+ElementName
public LoginPage enterUsername(String username) throws InterruptedException {
driver.findElement(By.name("USERNAME")).sendKeys(username);
// Thread.sleep(10000);
return this;
}
public LoginPage enterPassword(String password) {
driver.findElement(By.id("password")).sendKeys(password);
return this;
}
public HomePage clickLoginButton() {
driver.findElement(By.className("decorativeSubmit")).click();
return new HomePage(driver);
}
- Challenge 1: Ambiguity in Variable Names
Solution: Use “this” to distinguish between instance variables and local variables/parameters with the same names.
- Challenge 2: Method Overloading
Solution: When dealing with method overloading, “this” can help differentiate between instance methods and local methods with the same names.
Q.7. What is the difference between ArrayList and HashMap?
Explanation: In Java, an ArrayList is a dynamic array that can grow or shrink in size. It’s part of the java.util package and provides an ordered collection of elements. On the other hand, a HashMap is a collection of key-value pairs where each key is unique. It allows fast access to the values using the keys and is also part of the java.util package.
Scenario: In my project, you might use an ArrayList to store a collection of web elements, like a list of buttons on a page. A HashMap can be used to store dynamic data, like key-value pairs for storing input data and expected results for test cases.
Code Snippet:
// ArrayList Example
import java.util.ArrayList;
import java.util.List;
public class ArrayListExample {
public static void main(String[] args) {
List<String> buttonNames = new ArrayList<String>();
// Adding elements to ArrayList
buttonNames.add("Submit");
buttonNames.add("Cancel");
buttonNames.add("Login");
// Accessing elements
for (String button : buttonNames) {
System.out.println("Button Name: " + button);
}
}
}
java
// HashMap Example
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
Map<String, String> testData = new HashMap<String>();
// Adding key-value pairs to HashMap
testData.put("Username", "user1");
testData.put("Password", "pass123");
testData.put("ExpectedResult", "Login Successful");
// Accessing values using keys
System.out.println("Username: " + testData.get("Username"));
System.out.println("Password: " + testData.get("Password"));
System.out.println("Expected Result: " + testData.get("ExpectedResult"));
}
}
- Challenge 1: Maintaining Order
Solution: If order matters, use LinkedHashMap instead of HashMap to maintain the order of key-value pairs.
- Challenge 2: Duplicate Keys in HashMap
Solution: Ensure keys in a HashMap are unique. If duplicates are needed, consider using a different data structure like ArrayList or a more complex object as a value.
Q.8. Could you explain Encapsulation and elaborate on how you’ve implemented that in your framework?
Explanation: Encapsulation is one of the four fundamental OOPs concepts. It is the bundling of data and the methods that operate on that data, restricting access to some of an object’s components. It helps in hiding the internal details of an object and protecting the integrity of its state.
Use Case: In our project, we’ve organized things neatly by using a technique called encapsulation, which is like putting our code in a protective bubble. Specifically, we’re dealing with a “driver” object, which helps with parallel execution (doing multiple things at once).Now, the special tool we’ve employed is called ThreadLocal. We’ve made it private and static, giving it a special place in our project. Think of it like a secret box that only our project knows about.To interact with this secret box, we’ve created a couple of functions: a “getter” and a “setter.” The getter lets us peek inside the box to see what’s there (the driver instance), and the setter allows us to put something new into the box (setting a new driver).So, whenever we need to use the driver in different parts of our project, we just call these getter and setter functions, making sure everything runs smoothly and doesn’t get mixed up. It’s like having a designated locker for our project’s important tool, making sure it’s always there when we need it!
Reference Links: Understanding Encapsulation in OOP
Code Snippet:
public class DriverInstance {
private static final ThreadLocal<RemoteWebDriver> remoteWebdriver = new ThreadLocal<RemoteWebDriver>();
public void setDriver(String browser, boolean headless) {
switch (browser) {
case "chrome":
ChromeOptions options = new ChromeOptions();
options.addArguments("--start-maximized");
options.addArguments("--disable-notifications");
options.addArguments("--incognito");
remoteWebdriver.set(new ChromeDriver(options));
break;
case "firefox":
remoteWebdriver.set(new FirefoxDriver());
break;
case "ie":
remoteWebdriver.set(new InternetExplorerDriver());
case "edge":
remoteWebdriver.set(new EdgeDriver());
default:
break;
}
}
public static RemoteWebDriver getDriver() {
return remoteWebdriver.get();
}
}
- Concurrency Confusion:
-
Challenge: When multiple tasks are happening simultaneously (concurrency), it’s easy for things to get mixed up, like using the wrong tool at the wrong time.
-
Solution: We encapsulate our driver tool in a secret box (
ThreadLocal) to ensure that each task gets its own driver and they don’t interfere with each other.
-
- Data Security:
-
Challenge: It’s important to keep the driver tool safe and private, so it doesn’t accidentally get changed by another part of the project.
-
Solution: We’ve made the secret box (
ThreadLocal) private and static, like a locked box that only our project knows how to open.
-
- Easy Access:
-
Challenge: Users need a simple and reliable way to get and set the driver tool without worrying about the technical details.
-
Solution: We’ve created easy-to-use functions (getter and setter) that act like a window to peek inside the locked box. Users just call these functions when they need the driver, and everything is taken care of behind the scenes.
-
- Seamless Integration:
-
Challenge: Users want to seamlessly integrate the driver tool into different parts of the project without causing disruptions.
-
Solution: By encapsulating the driver and providing these simple functions, users can smoothly integrate the driver wherever needed, ensuring a seamless flow of work without any hiccups.
-
- Adaptability:
-
Challenge: Projects often evolve, and users need a solution that can adapt to changes without causing major rework.
-
Solution: The encapsulation approach with
ThreadLocaland simple functions makes it easy to adapt. If there are changes to how the driver is handled, users just need to update the getter and setter functions without affecting the rest of the project.
-
Q.9. Can you elaborate on the process of implementing serialization and deserialization in Java from a testing and quality assurance perspective?
Explanation: Serialization and deserialization are crucial processes in Java, especially in the context of testing and quality assurance. Serialization involves converting an object into a byte stream, which can be stored, transmitted, or reconstructed later. Deserialization is the reverse process, where the byte stream is used to recreate the object. These processes are vital for saving and restoring object states and for data exchange between applications.
Use Case: In our testing framework, we leverage serialization and deserialization to manage test data efficiently. For a scenario where test data objects need to be created and reused across different test cases. Serialization allows us to store these objects as files, and deserialization enables us to retrieve them when needed. This ensures data consistency and eliminates the need to recreate test data for each test, making our test suite more efficient.
Code Snippet (Serialization):
import java.io.*;
public class TestDataSerialization {
public static void serializeTestData(TestDataObject testData, String filePath) throws IOException {
try (ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(filePath))) {
out.writeObject(testData);
}
}
}
Java Code Snippet (Deserialization):
java
import java.io.*;
public class TestDataDeserialization {
public static TestDataObject deserializeTestData(String filePath) throws IOException, ClassNotFoundException {
try (ObjectInputStream in = new ObjectInputStream(new FileInputStream(filePath))) {
return (TestDataObject) in.readObject();
}
}
}
-
Challenge 1: Serialized data should maintain integrity during storage and transmission to ensure accurate test results.
Solution: Regularly we validate the deserialized data against expected values to catch any discrepancies, ensuring data integrity in the testing process.
-
Challenge 2: Changes in the structure of the test data object may affect deserialization.
Solution: We usually implement version control mechanisms and backward compatibility checks to handle changes gracefully and avoid disruptions in the testing workflow.
-
Challenge 3: Serialized data can be vulnerable to tampering, posing a security risk.
Solution: We apply encryption and checksum mechanisms to enhance the security of serialized data, especially when dealing with sensitive test information.
In summary, serialization and deserialization in Java, when strategically implemented, enhance the efficiency and reliability of test data management in a testing and quality assurance framework. These processes play a vital role in maintaining data consistency, optimizing test execution, and addressing various challenges associated with data integrity and security.
Q.10. How would you describe the significance and implementation of marker interfaces in Java?
Explanation: A marker interface in Java is an interface with no methods, serving as a tag to indicate a capability or a characteristic that a class implements. It doesn’t declare any methods, but classes implementing the marker interface express that they possess a certain behavior or property.
Use Case: In my project, we want to identify certain classes as eligible for serialization. we define a marker interface, say SerializableMarker, and have classes that should be serializable to implement this interface. During runtime, we can check if an object is an instance of this interface to decide whether it can be serialized.
Code Snippet:
// Marker Interface
public interface SerializableMarker {
// Marker interfaces do not have any methods
}
// Class implementing the marker interface
public class SerializableClass implements SerializableMarker {
// Class implementation
}
Exception Handling: Marker interfaces themselves do not involve exception handling since they don’t have methods. However, when using marker interfaces in your code, exceptions might occur depending on the context in which they are used. For example, when checking if an object is an instance of a marker interface, a ClassCastException might occur if the object is not of the expected type.
if (someObject instanceof SerializableMarker) {
// Serialization logic
} else {
// Handle the case where the object is not serializable
}
- Challenge 1: Ensuring that marker interfaces are used consistently.
Solution: We usually document the purpose of marker interfaces clearly and encourage developers to adhere to their usage. Automated tools or code reviews can help catch instances where marker interfaces are not implemented correctly.
-
Challenge 2: Marker interfaces don’t provide any compile-time checks, so it might be challenging to ensure that all relevant classes implement the marker interface.
Solution: Regular code reviews, unit testing, and static analysis tools can help identify missing implementations of marker interfaces. Additionally, we use annotations or other mechanisms that offer stronger compile-time checks.
Q.11. Could you explain how method overloading works in Java?
Explanation: Overloading means, a same class can have multiple methods with the same name but different parameter lists (different data types or a different number of parameters). The purpose of method overloading is to simplify verbose. (When you have multiple methods with similar functionality but different parameter sets, it becomes easier for developers to identify which method to use based on the context)
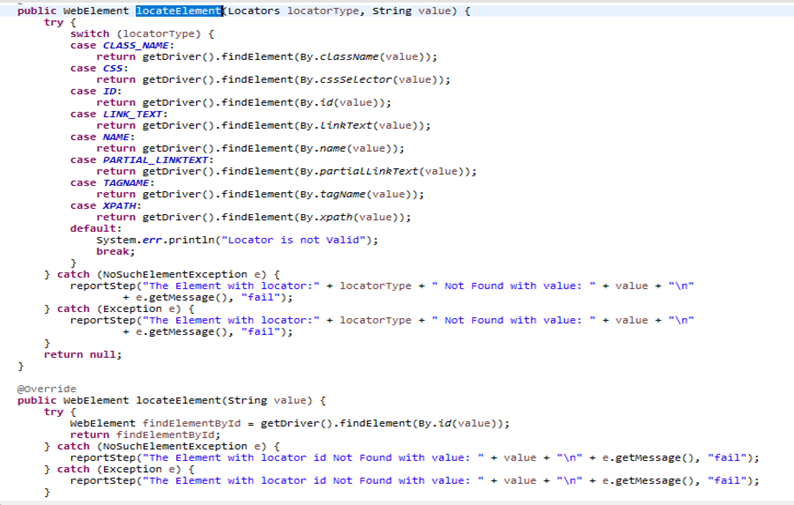
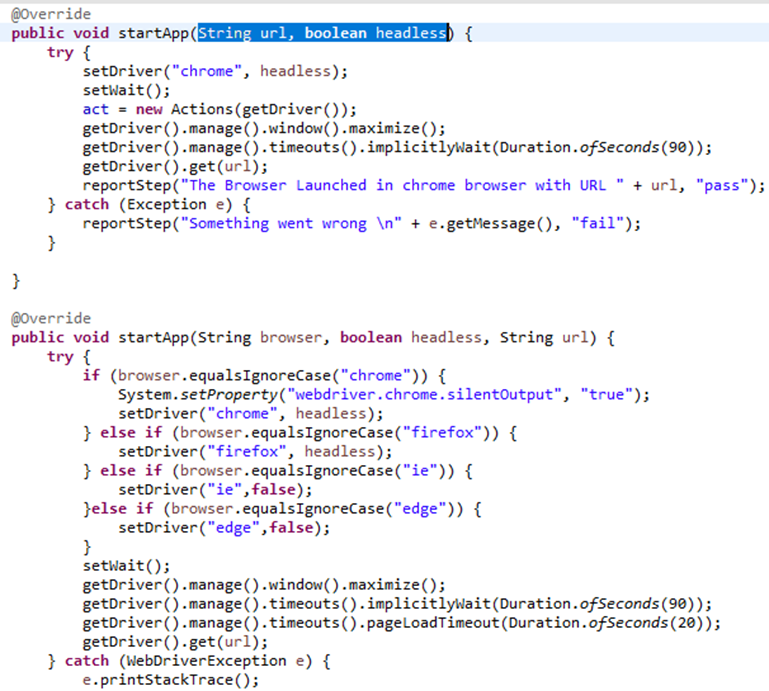
Use Case: In my framework, we have many method overloading methods, some of them are locateElement(),startApp()
- Example 1: locateElement()
In the SeleniumBase Class, there are two ways to find an element. The first method is calledlocateElement(String value), where we should only need to provide a string value, usually the value of id locator. The second method islocateElement(Locator locatorType, String value), where we can give two things: the type of locator to use (like ID or something else) and the value of that locator to find the element. - Example 2: startApp()
In SeleniumBase, there are two ways to begin using an application based on its web address (URL). The first method is calledstartApp(String url, boolean headless). With this method, you provide the URL as a string and a boolean value to indicate whether to start the application in a hidden (headless) mode. By default, it uses the Chrome browser. The second method isstartApp(String browser, boolean headless, String url). Here, you give three things: the specific browser you want to use (like Chrome or Firefox), whether you want it to be in headless mode,and the URL of the application you want to load. -
Code Snippet:
Challenges and Solutions:
-
-
Challenge: Ambiguity in method resolution if the compiler cannot determine the most specific method based on the provided arguments.
Solution: We carefully design the overloaded methods to have distinct parameter lists. If ambiguity arises, resolve it by explicitly casting the arguments or choosing the method with the most specific parameter types.
-
Challenge: Understanding which method will be called can be challenging for developers, especially when dealing with complex class hierarchies.
Solution: We Follow good naming conventions, document the purpose of each overloaded method, and provide clear method signatures to make it easier for developers to understand which method to use in a given context.
-
Q.12. Can you explain the distinctions between method overloading and method overriding in Java, highlighting their key characteristics and use cases?
Explanation: Method overloading and Method overriding are both features in Java related to polymorphism.
-
-
Method Overloading: Overloading means, the same class can have multiple methods with the same name but different parameter lists (different data types or a different number of parameters). The purpose of method overloading is to simplify verbose. (When you have multiple methods with similar functionality but different parameter sets, it becomes easier for developers to identify which method to use based on the context)
-
Method Overriding: Method overriding is a concept in object-oriented programming (OOP) where a subclass (child class) provides a specific implementation for a method that is already defined in its superclass (parent class). The subclass modifies the behavior of the method to suit its own needs while keeping the method signature (name and parameters) the same as in the parent class.
-
Use Case:
In a web project, you might have a base class Shape with a method calculateArea(). You can use method overloading to provide different implementations of calculateArea() for different shapes like circles, rectangles, and triangles. Additionally, you can use method overriding to customize the calculateArea() method in subclasses, providing specific formulas for each shape.
Code Snippet:
// Method Overloading
class Shape {
double calculateArea(double side) {
return side * side; // Area of a square
}
double calculateArea(double length, double width) {
return length * width; // Area of a rectangle
}
}
// Method Overriding
class Circle extends Shape {
double radius;
@Override
double calculateArea(double radius) {
return Math.PI * radius * radius; // Area of a circle
}
}
-
-
Challenge 1: Signature Matching: Ensuring that the overridden method has the correct signature can be challenging. I addressed this by carefully checking and matching the method name, return type, and parameters in both the superclass and subclass.
-
Challenge 2: Understanding Runtime Polymorphism: grasping the concept of runtime polymorphism, especially when dealing with complex class hierarchies, can be challenging. I tackled this by practicing and creating simple examples to solidify my understanding.
-
Q.13. In your projects, have you encountered situations where multiple catch blocks were used without a try block, and if so, could you describe the specific scenarios and how you addressed them in terms of error handling or exception management?
Explanation: In Java, it’s not possible to have multiple catch blocks without a try block. The basic syntax for exception handling involves enclosing the code that might throw an exception within a try block, followed by one or more catch blocks to handle different types of exceptions. However, if we meant multiple catch blocks within the same try block, we can certainly provide insights into that scenario.
Use Case:
In my projects, we often encounter situations where various exceptions can be thrown during test execution. When interacting with web elements, exceptions like NoSuchElementException , StaleElementReferenceException, or TimeoutException may occur.
public class SeleniumExample {
public void performAction() {
try {
// Selenium code that might throw exceptions
WebElement element = driver.findElement(By.xpath("//some/xpath"));
element.click();
} catch (NoSuchElementException e) {
// Handling the exception when the element is not found
System.out.println("Element not found: " + e.getMessage());
} catch (StaleElementReferenceException e) {
// Handling the exception when the element is no longer attached to the DOM
System.out.println("Stale element reference: " + e.getMessage());
} catch (TimeoutException e) {
// Handling the exception when an operation times out
System.out.println("Timeout: " + e.getMessage());
} catch (Exception e) {
// Generic catch block for handling any other exceptions
System.out.println("An unexpected error occurred: " + e.getMessage());
}
}
}
-
Specific Exception Handling: Each catch block is designed to handle a specific type of exception. This allows for more precise error messages and actions based on the nature of the exception.
-
Generic Exception Handling: The last catch block with the
Exceptiontype acts as a catch-all for any other unexpected exceptions. This provides a fallback mechanism to log or handle unforeseen issues gracefully. -
Logging: In each catch block, it’s advisable to log the exception details, helping in troubleshooting and debugging. Logging frameworks like Log4j or the built-in Java logging can be utilized.
-
Maintainability: This approach makes the code more maintainable. If new exception types need to be handled in the future, you can easily add new catch blocks without modifying the existing ones.
Challenges: One challenge is to strike the right balance between specific and generic exception handling. Overusing generic exception handling might hide important details about the cause of the failure.
In summary, utilizing multiple catch blocks within a try block in Selenium projects allows for tailored exception handling, logging, and better management of unexpected issues during test execution.
Q.14. How do you utilize the ‘super’ keyword in Java to enhance the functionality or solve specific challenges in your automation testing projects, especially when working with Selenium, Java, and TestNG frameworks?
Explanation: The ‘super’ keyword in Java is a reference variable used to refer to the immediate parent class object. It is particularly useful in scenarios where a subclass needs to access or invoke the members of its superclass.
Scenario: In my project, we faced a scenario where a base page class is implemented to initialize the WebDriver and common functionalities, and this class is then extended by multiple page classes representing different pages of the web application.
Code Snippet:
public class BasePage {
protected WebDriver driver;
public BasePage(WebDriver driver) {
this.driver = driver;
} // Common methods for page initialization, etc.
}// HomePage.java
public class HomePage extends BasePage {
public HomePage(WebDriver driver) {
super(driver);
} // Additional methods specific to the home page
}
Exceptions:
Handling potential exceptions like NullPointerException. To mitigate this, explicit checks were implemented to ensure that the WebDriver is initialized before using it in any subclass method.
Q.15. How does Java manage garbage collection to efficiently handle memory and prevent memory leaks in your programming projects?
Explanation: Garbage collection in Java automates the process of identifying and removing unused objects, optimizing memory usage in the Java Virtual Machine (JVM) during program execution. It prevents memory leaks by reclaiming space occupied by objects that are no longer needed.
Scenario: In my project, we faced a scenario where multiple page objects are created during the test execution to represent different pages of a web application. As the test progresses, some of these page objects become obsolete, and their memory can be reclaimed through garbage collection.
Code Snippet:
public class WebPage {
private String pageContent;
public WebPage(String pageContent) {
this.pageContent = pageContent;
}
// Other methods related to the web page
public void navigateToAnotherPage() {
// Code to navigate to another page
}
}
// In the test script
public class TestScript {
public static void main(String[] args) {
WebPage page1 = new WebPage("Page 1 content");
// Test actions on page1
WebPage page2 = new WebPage("Page 2 content");
// Test actions on page2
// At this point, page1 is no longer needed
page1 = null;
// Perform more test actions
// Garbage collection may occur, reclaiming the memory occupied by page1
}
}
Q.16. How would you describe the use and significance of method references in Java?
Explanation:
Method references in Java provide a concise way to express lambda expressions when calling a method. They enable you to refer to a method by its name instead of providing a delegate to the method. Method references are often more readable and can make your code more compact.
There are several types of method references:
Static Method Reference:
Syntax: ClassName::staticMethodName
Example: Integer::parseInt
Instance Method Reference of a Particular Object:
Syntax: instance::instanceMethodName
Example: System.out::println
Instance Method Reference of an Arbitrary Object of a Particular Type:
Syntax: ClassName::instanceMethodName
Example: String::length Constructor
Method Reference: Syntax: ClassName::new
Example: ArrayList::new
Scenario:
In my project, we have a scenario where we have a list of strings and we want to convert each string to uppercase. Instead of using a lambda expression, a method reference could be employed to directly reference the toUpperCase method of the String class.
Code Snippet:
List<String> words = Arrays.asList("apple", "banana", "orange");
// Using Lambda Expression
words.forEach(word -> System.out.println(word.toUpperCase()));
// Using Method Reference
words.forEach(System.out::println);
-
Ensuring Method Reference Compatibility: Ensuring that the method reference matches the signature of the functional interface’s single abstract method is essential. Mismatched method signatures can lead to compilation errors, making it challenging to identify and resolve the issue.
Solution: We regularly review the documentation and specifications of the functional interfaces being used and pay close attention to parameter types and return types to ensure compatibility. Comprehensive testing and code reviews can help catch and address compatibility issues early in the development process.
Q.17. How have you leveraged the getClass() method in Java to gain practical insights into object types and facilitate effective decision-making or processing in your projects?
Explanation: The getClass() method in Java is used to obtain the runtime class of an object. It returns an instance of the Class class, which provides methods to analyze and manipulate information about the class to which the object belongs.
Scenario: Dynamic Reporting in Selenium Test Automation Framework
In a Selenium test automation framework where test results need to be dynamically reported based on the type of web elements interacted with during test execution. The getClass() method can be utilized to capture the runtime class of web elements and generate detailed reports.
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
public class SeleniumTestReporter {
private WebDriver driver;
public SeleniumTestReporter(WebDriver driver) {
this.driver = driver;
}
public void reportElementInteraction(By locator) {
WebElement element = driver.findElement(locator);
Class<?> elementClass = element.getClass();
// Logging information about the element class and interaction
Logger.log("Interacted with element of type: " + elementClass.getName() + " located by: " + locator);
// Additional reporting logic, e.g., capturing screenshots, logging to a report file, etc.
// ...}}
public class TestScenario {
private WebDriver driver;
private SeleniumTestReporter testReporter;
@BeforeClass
public void setup() {
// WebDriver initialization...
driver = new ChromeDriver();
testReporter = new SeleniumTestReporter(driver);
}
@Test
public void testLogin() {
By usernameLocator = By.id("username");
By passwordLocator = By.id("password");
By loginButtonLocator = By.id("loginButton");
// Perform login interactions
testReporter.reportElementInteraction(usernameLocator);
driver.findElement(usernameLocator).sendKeys("testuser");
testReporter.reportElementInteraction(passwordLocator);
driver.findElement(passwordLocator).sendKeys("pass123");
testReporter.reportElementInteraction(loginButtonLocator);
driver.findElement(loginButtonLocator).click();
// Additional test steps...
}
}
- Challenge 1: Handling Null Objects
To address the potential NullPointerException, explicit checks were implemented at the beginning of the process method to ensure that the input object is not null. If null, appropriate handling or default processing logic is applied.
- Challenge 2: Maintenance of Conditional Checks
As the number of supported data types increased, maintaining the conditional checks became challenging. To address this, a more modular and extensible approach was adopted, utilizing a mapping between data types and corresponding processing strategies. This made it easier to add or modify data types without modifying the core processing logic.
Q.18. How have you practically employed list sorting techniques in Java to efficiently organize and manage data in your development projects? Walk me through a specific scenario where you implemented list sorting, and share insights into the code and challenges faced during the process.
Explanation:
Sorting a list in Java involves arranging its elements in a specific order, either in ascending or descending fashion. The Collections.sort() method or the sort() method of the List interface is commonly used for this purpose.
Scenario:
In my project, a common scenario involved extracting data from a table on a web page, such as a list of product prices or user names, and dynamically sorting this data based on specific criteria. This functionality was implemented to provide users with the ability to view the data in ascending or descending order.
Code Snippet:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class ListSortingExample {
public static void main(String[] args) {
// Example list of product prices
List<Double> productPrices = new ArrayList<Double>();
productPrices.add(19.99);
productPrices.add(29.99);
productPrices.add(14.99);
productPrices.add(39.99);
// Sorting the list in ascending order
Collections.sort(productPrices);
// Printing the sorted list
System.out.println("Sorted Product Prices (Ascending): " + productPrices);
// Sorting the list in descending order
productPrices.sort(Collections.reverseOrder());
// Printing the sorted list in descending order
System.out.println("Sorted Product Prices (Descending): " + productPrices);
}
}
Q.19. How can you distinguish between using an interface and an abstract class in your project? Can you share a specific scenario where you decided to implement one over the other, walk me through the implementation, and highlight any challenges you encountered?
Explanation:
In Java, an abstract class is a class that cannot be instantiated and may contain abstract methods, while an interface is a collection of abstract methods and constants.
Scenario:
In my project, a scenario involved creating a common set of methods for interacting with various web elements like buttons and text fields. An abstract class named BasePage was implemented to provide default implementations for common methods, such as clicking a button or entering text. This abstract class was then extended by specific page classes, allowing for code reuse and consistency across the project.
Code Snippet:
public abstract class BasePage {
public abstract void clickButton(String buttonId);
public abstract void enterText(String textFieldId, String text);
// Common method with a default implementation
public void navigateTo(String url) {
System.out.println("Navigating to: " + url);
// Additional navigation logic
}
}// Page class example
public class LoginPage extends BasePage {
@Override
public void clickButton(String buttonId) {
System.out.println("Clicking button with ID: " + buttonId);
// Clicking logic
} @Override
public void enterText(String textFieldId, String text) {
System.out.println("Entering text '" + text + "' into text field with ID: " + textFieldId);
// Text entry logic
}}
-
Challenge 1: Evolution of Codebase: As the project evolves, modifying an abstract class may require changes in all its subclasses, potentially leading to a ripple effect. Managing and versioning the evolving codebase while minimizing disruption can be challenging.
Solution: We use interfaces and abstract classes judiciously. When changes are anticipated, consider using interfaces or providing well-documented extension points in abstract classes to facilitate future modifications. -
Challenge 2: Interfaces in Java cannot have constructors, making it challenging to initialize state or resources. If an object requires complex initialization, an abstract class might be a more suitable choice.
Solution: Use abstract classes if the implementation requires a common constructor logic. If possible, delegate construction logic to factory methods or consider using a combination of abstract classes and interfaces.
Q.20. Describe the purpose of the object class in Java.
Explanation:
The Object class in Java is the root class for all classes and is implicitly inherited by every class. It provides fundamental methods, such as toString(), equals(), and hashCode(), which can be overridden to tailor the behavior of objects based on specific project requirements.
Scenario:
In my project, the Object class can be leveraged to enhance logging capabilities, providing more meaningful information about web elements and their interactions. For a scenario, where a custom WebElementWrapper class extends the Object class to override the toString() method.
Code Snippet:
import org.openqa.selenium.WebElement;
public class WebElementWrapper extends Object {
private WebElement webElement;
public WebElementWrapper(WebElement webElement) {
this.webElement = webElement;
} // Other methods and functionalities
@Override
public String toString() {
// Customized toString method for logging purposes
return "WebElement with attributes: " + webElement.toString();
}
}
Q.21. In the context of Java or Selenium automation, how have you practically utilized abstract classes, and what benefits do they bring to the development or testing process?
Explanation:
Abstract classes in Java are classes that cannot be instantiated on their own and often serve as blueprints for other classes. They may include abstract methods, providing a structure that derived classes must implement. Abstract classes allow for the creation of common methods and fields shared among multiple related classes, promoting code reuse and a more organized class hierarchy.
Scenario:
In my project where different web pages share common functionalities like login or navigation. An abstract class BasePage can be created to encapsulate these shared functionalities, ensuring consistency across page objects.
Code Snippet:
public abstract class BasePage {
WebDriver driver;
public BasePage(WebDriver driver) {
this.driver = driver;
} public abstract void navigateTo(String url);
public void login(String username, String password) {
// Implementation of login functionality common to all pages
}
// Other common methods...
} public class HomePage extends BasePage {
public HomePage(WebDriver driver) {
super(driver);
} @Override
public void navigateTo(String url) {
// Implementation specific to the home page
}
Challenge and Solution:
Managing Dependency Injection in scenarios where dependencies, such as the WebDriver instance, need to be injected into the abstract class, managing this dependency injection efficiently across multiple derived classes can be challenging. Utilizing dependency injection frameworks or carefully designing constructors can help address this challenge.
Q.22. Could you explain the differences between HashSet and HashMap and provide examples
Explanation:
Both HashSet and HashMap are essential data structures in Java. HashSet is used to store a collection of unique values, ensuring that each element is distinct. On the other hand, HashMap is employed to store key-value pairs, facilitating a two-dimensional relationship where values are associated with unique keys.
UseCase:
In my project, we had a scenario where we need to manage user permissions. So we use a HashSet to store unique permission types, ensuring that each permission is unique. Meanwhile, a HashMap is employed to associate each user with a set of permissions, where the user ID acts as the key and the associated permissions as the values.
Reference Links:
Code Snippet:
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
public class PermissionManager {
public static void main(String[] args) {
// HashSet for unique permission types
Set<String> permissionSet = new HashSet<>();
permissionSet.add("READ");
permissionSet.add("WRITE");
permissionSet.add("DELETE");
// HashMap for associating users with permissions
Map<Integer, Set<String>> userPermissions = new HashMap<>();
userPermissions.put(1, permissionSet);
userPermissions.put(2, new HashSet<>(Set.of("READ")));
// Retrieving permissions for a specific user
Set<String> user1Permissions = userPermissions.get(1);
System.out.println("User 1 Permissions: " + user1Permissions);
}
}
Challenge and Solution:
- Handling Null Values:
Dealing with null values when retrieving permissions required additional checks to avoid potential
NullPointerExceptions. Using conditional statements to verify the existence of the user before accessing their permissions resolved this challenge.





